为啥写这篇文章呢,起因其实是因为收到了一个神秘的链接,也就是下面的万恶之源,然后让我又涨了新姿势
这本质上是一个javascript的正则表达式锻炼网站,学习网站。
在写level 2的时候,踩入了一个深坑,想了半天也么想到一个好的有效的办法,当时就懵了
本质上是匹配ipv6的地址,题目如下
Jan 13 00:48:59: DROP service 68->67(udp) from 213.92.153.167 to 69.43.107.219, prefix: "spoof iana-0/8" (in: eth0 69.43.112.233(38:f8:b7:90:45:92):68 -> 217.70.100.113(00:21:87:79:9c:d9):67 UDP len:576 ttl:64)
Jan 13 12:02:48: ACCEPT service dns from 74.125.186.208 to firewall(pub-nic-dns), prefix: "none" (in: eth0 74.125.186.208(00:1a:e3:52:5d:8e):36008 -> 140.105.63.158(00:1a:9a:86:2e:62):53 UDP len:82 ttl:38)其中,要匹配的是 38:f8:b7:90:45:92 这样的地址
当时我的想法是通过()来限定范围,然后再在限定的范围内去处理这些文字,通过单纯的匹配’(‘是会将’(‘也匹配到内容中去的,所以一下子没了头绪。(其实简单的解法是直接用([\w\d]+:){5}[\w\d]+ 来进行匹配)
经过一番搜索,在搜索关键词为 如何匹配括号范围里的内容长得很香不可描述网站的技术网站 的时候,一个新的词进入了我的视线————零宽断言
零宽断言
资料参考:正则表达式零宽断言详解(?=,?<=,?!,?<!)
一.基本概念:
零宽断言正如它的名字一样,是一种零宽度的匹配,它匹配到的内容不会保存到匹配结果中去,最终匹配结果只是一个位置而已。(就跟^和$的作用一样)
作用是给指定位置添加一个限定条件,用来规定此位置之前或者之后的字符必须满足限定条件才能使正则中的字表达式匹配成功。
二、用法
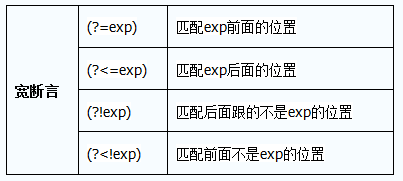
三、在第二题中的用法
(?<=\()(?!udp)([\d\w:]+)(?=\))上方的匹配方法为:
(?<=() 为 以 ( 为起始
(?=)) 为 以 ) 为结束,
(?!udp) 为 排除中间为udp的
([\d\w:]+) 为匹配 数字 字符串 :
进行匹配。排除udp的方式有点蠢,不知道有啥更好的办法可以将非 : 拼接的字符串去除,所以直接对udp进行了排除,简单粗暴,请容许我偷懒一下-w-
结语
以前最多用的正则表达式其实就是简单的字符匹配,从来没用过零宽断言这种神秘的东西。在解前几题的时候其实没发现零宽断言有什么好用的,在做最后几题的时候发现零宽断言对限定范围匹配的支持非常好,写起来特别快
写的过程中还有一个就是非贪婪匹配,也解决了很多复杂的问题,下一篇就讲一下非贪婪匹配
感觉正则表达式的面纱又被窝揭掉了一层hiahiahia
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!